OpenAI或推出GPT-5,商标申请进展曝光
【本站】8月10日消息,近日根据国家知识产权局商标局官网的披露,欧爱运营有限责任公司(OPENAI OPCO, LLC)在上月下旬已提交了两份商标注册申请,申请商标为GPT-5,分别归属于国际分类9类和42类,其中包括科学仪器以及设计研究。这两个商标目前处于申请中的状

更新日期:2023-07-25
来源:系统之家
【本站】7月25日消息,近日,北京知未智能科技有限公司在上海举行发布会,正式推出知未智能 KDF 大模型,以及一系列基于该模型研发的金融行业工具,为相关行业的产业发展助力。
知未智能 KDF 大模型是一款专注于金融和商业领域的中文模型。在其训练数据中,以中文为主,融合了大量的金融数据,从而大幅提升了模型在商业和金融问题处理方面的能力。
值得一提的是,为了保证模型的通用能力,训练数据还融合了部分英文和代码数据,以确保模型具备处理多种任务的能力。在训练过程中,知未智能 KDF 大模型采用了基于 PyTorch 优化的 GELU 非线性激活函数,这种优秀的激活函数有助于更精确地捕获复杂数据特征,保障了整个开发、训练和部署过程的高效运行。
为了在保证效果的同时提高可扩展性,开发团队对模型的网络结构进行了深度优化。与 LLaMA 模型相比,知未智能 KDF 大模型在每一层使用更少的参数,有效降低了计算需求和内存占用。与此同时,网络深度也得到了加强,从而让模型具备了更强大的表示能力,能够学习到更为复杂的数据特征。
据本站了解,在训练过程中,开发团队还重新调整了注意力层的 Bias,并引入了 Flash Attention 技术,以节省显存并提高模型训练和推理速度。得益于这项技术的应用,知未智能 KDF 大模型在有限的硬件资源下也能实现更高效的运行。
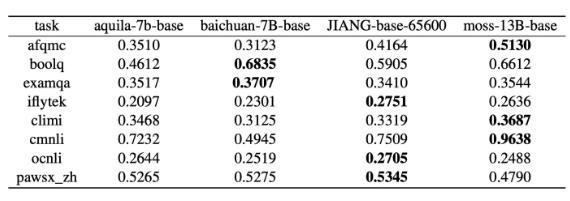
基准测试结果显示,知未智能 KDF 大模型在七个自然语言处理任务中展现出稳定的性能。在一些任务中,如 iFlytek 和 CMNLI,其表现相对出色。在 ExamQA 和 OCNLI 测试中,各模型的表现大致相同,凸显了该模型处理不同类型文本和领域知识方面的能力。
CEO 段清华表示,现有通用大模型在具体行业应用性和中文能力方面存在局限性,因此知未智能选择从零开始训练 KDF 大模型,以提升其中文能力和行业适用性。他强调,在打造这款“功能强大、性能优越”的中文模型过程中,开发团队深入理解技术细节,并将持续推动公司产品的开发创新。
目前,知未智能 KDF 大模型已在Hugging Face上开源,并将不限制商业使用,为行业发展和应用提供更多可能性。
OpenAI或推出GPT-5,商标申请进展曝光
【本站】8月10日消息,近日根据国家知识产权局商标局官网的披露,欧爱运营有限责任公司(OPENAI OPCO, LLC)在上月下旬已提交了两份商标注册申请,申请商标为GPT-5,分别归属于国际分类9类和42类,其中包括科学仪器以及设计研究。这两个商标目前处于申请中的状
生成式AI服务管理不影响企业科研攻关及自动驾驶等领域
【本站】8月9日消息,近日,ISC2023第11届互联网安全大会上,中央网信办网络安全协调局副局长罗锋盈发表了关于生成式人工智能服务管理暂行办法的演讲。根据罗锋盈的表示,该办法将于8月15日正式实施,旨在规范生成式人工智能服务领域,但不会影响到自动驾驶等

Azure AI文本转语音升级:男声"Ryan"登场,语言支持大幅扩展
【本站】8月9日消息,微软Azure持续加强其基于云的服务和功能,最新宣布升级了Azure AI文本转语音,为企业用户带来更加多样化和逼真的体验。其中引人注目的是,该升级不仅增加了更多语言支持,还引入了全新的男声Ryan Multilingual,为用户创造出更具多元性和

微软研究院展示"Project Rumi":多模态AI项目助力理解人类意图
【本站】8月5日消息,近日,微软研究院展示了名为Project Rumi的创新项目。该项目旨在提升人工智能系统的理解能力,实现对人类意图的更深入理解。目前,虽然人工智能在自然语言处理领域取得了长足的进步,但现有的NLP AI主要仅依赖于文本输入输出,忽略了人类

阿里云通义千问:开源免费、助力企业打造专属大模型
【本站】8月3日消息,阿里云在今日宣布开源了两款庞大的语言模型——通义千问(Qwen-7B)和对话模型(Qwen-7B-Chat),这两个模型的参数规模达到70亿,成为了国内首个加入大模型开源行列的大型科技企业。据了解,通义千问在今年4月份已经发布,并得到了积极的市场

苏姿丰:预计今年下半年PC市场将因AI需求增长而复苏
【本站】8月2日消息,AMD CEO苏姿丰近日表示,预计PC市场将在今年下半年迎来季节性增长,并且供应链库存水平也将有所改善。在与分析师的电话会议中,苏姿丰表示,AMD在第二季度表现良好,推出了多种领先解决方案,同时还扩展了AI业务,这使得第二季度营收较去

智能化改进助力宝马生产线:AI降低成本提高效率
【本站】7月25日消息,据外媒CNBC报道,宝马近日在位于斯帕坦堡的工厂引入了人工智能技术,旨在优化制造流程、提高效率并改进品控。据悉,这一AI工具主要应用于宝马的车身车间,通过检测机械臂焊接过程中可能出现的问题,实现自动修复,从而取代了部分专项工

英特尔与埃森哲联手推出34个开源AI参考套件,助力AI部署
【本站】7月25日消息,英特尔今日宣布与埃森哲(Accenture)达成合作,共同推出了34个开源AI参考套件。这些参考套件旨在简化和加快数据科学家和开发人员在部署人工智能方面的工作。每个开源AI参考套件都包含模型代码、训练数据、设置机器学习管道的说明,以及库

人工智能芯片市场潜力巨大 台积电或获新发展契机
【本站】7月21日消息,随着全球消费电子产品需求的下滑和芯片需求减少,台积电等芯片代工商也受到了影响。台积电的营收已连续三个季度环比下滑,净利润也已连续两个季度下滑。据本站了解,在当前的形势下,全球消费电子产品市场依然不乐观,对芯片

GitHub Copilot Chat企业测试版发布:AI智能助手为开发者提供代码支持和交互体验
【本站】7月21日消息,微软旗下的代码托管平台GitHub日前发布了Copilot Chat的公开测试版,这是一款AI工具,专为开发者编写代码提供帮助,并能直接集成到开发者的桌面IDE环境中。据了解,Copilot Chat的功能不仅局限于填补代码缺省和纠错,它还可以根据上文自

LG发布EXAONE 2.0:支持多模态语言处理的大语言模型
【本站】07月20日消息,LG公司于昨晚发布了最新的多模态大语言模型EXAONE 2.0。这款模型支持韩语和英语,并可应用于新材料、新药开发等领域。据了解,EXAONE 2.0采用了轻量化设计,以解决超大型AI的高成本问题。该模型通过学习了约4500万件专业文献、专利和论

LG发布EXAONE 2.0:支持多模态语言处理的大语言模型
【本站】07月20日消息,LG公司于昨晚发布了最新的多模态大语言模型EXAONE 2.0。这款模型支持韩语和英语,并可应用于新材料、新药开发等领域。据了解,EXAONE 2.0采用了轻量化设计,以解决超大型AI的高成本问题。该模型通过学习了约4500万件专业文献、专利和论

斯坦福大学和加州大学伯克利分校的研究:GPT-4智能下降
【本站】07月20日消息,来自斯坦福大学和加州大学伯克利分校的研究团队最近对GPT-4进行了深入研究,并发现在处理数学问题、生成执行代码和完成视觉推理任务方面,该模型的智能水平显著下降。研究人员使用了数学问题来评估GPT-4的数学能力,其中一个例子是判断

斯坦福大学和加州大学伯克利分校的研究:GPT-4智能下降
【本站】07月20日消息,来自斯坦福大学和加州大学伯克利分校的研究团队最近对GPT-4进行了深入研究,并发现在处理数学问题、生成执行代码和完成视觉推理任务方面,该模型的智能水平显著下降。研究人员使用了数学问题来评估GPT-4的数学能力,其中一个例子是判断

华为联合山东能源集团实现矿山领域AI落地,开创工厂化开发模式
【本站】7月18日消息,华为联合山东能源集团今日举行发布会,宣布华为盘古大模型在矿山领域取得了重要突破,并首次投入商业应用。这一进展将为人工智能在矿山领域的落地难题提供解决方案,引领矿山AI开发模式向工厂化转型,为AI在矿山领域的大规模应用奠定坚
